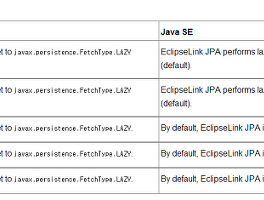
JPA 썸네일형 리스트형 JPA 페이징 http://wiki.eclipse.org/EclipseLink/Examples/JPA/Pagination 위 내용 중 쉽게 쓸만 한 것은 아래 코드이다. Query query = em.createQuery("SELECT e FROM Employee e ORDER BY e.lastName ASC, e.firstName ASC"); query.setFirstResult(5); query.setMaxResults(5); List emps = query.getResultList(); 예제에는 오라클이라 되어 있는데 MySQL도 사용 가능하다. JPA LAZY 로딩이 안될때.. 설치된 Java 환경이 SE 인가 EE인가 살펴보자.. one-to-one 및 many-to-one일 경우 SE 환경에서는 JPA가 fetch 무시하고 EAGER로 적용해버린다. 고로.. SE에서는 쓸모가 없다.. ;; JPA 예제 및 설명 사이트. http://www.java2s.com/Code/Java/JPA/CatalogJPA.htm 잘 되어 있고 코드도 어렵지 않다. http://www.objectdb.com/java/jpa/persistence JPA 각 클래스 및 짤막한 예제 코드가 있는 곳. [JPA 따라하기] 3. DB에서 Table 읽어오기. src 하위에 자신만의 package를 생성한다. 만든 패키지에서 우클릭 후 JPA Entities from Tables를 눌러 아래 화면으로 이동한다. 만약, MySQL Workbench를 이용한다면 DB 모델링을 끝마친후 DB를 생성한 다음 이 작업을 하게 되는데 모델링된 결과를 바로 Java로 가지고 올 수 있어 편하다. 프로젝트 생성시 만들었던 DB Connection을 이용해 DB내의 Table 정보를 보여준다. Java로 가져올 Table(Entity)를 선택한다. 만약 Entity간의 관계가 설정이 되어 있다면 자동으로 관계를 설정해준다. 이는 Entity 설정에 의한 자동 매핑으로 Entity에 관계 설정이 없다면 단일 테이블(Entity)로 판단하고 관계를 생성하지 않는다. 먼저 PK 생.. [JPA 따라하기] 2. JPA 프로젝트 생성 중간에 보이는 Configuration을 바꿔주어야 한다. 여기서 그냥 Finish를 눌러서 프로젝트 정보에서도 가능하나, 만들때 하기로 한다. Modify를 누러서 진행 JPA를 선택하고 Runtimes에 Tomcat을 선택한다. 현재 JPA Version은 2.0으로 되어 있다. 플랫폼은 EclipselInk 2.4를 사용할 것이고 해당 라이브러리는 Download 버튼을 누르면 아래처럼 창이 나온다. 각 환경에 맞는 EclipseLink를 선택한 후 Next를 눌러 다운로드를 완료한다. JPA에 필요한 Hibernate 관련 라이브러리를 추가해주어야 한다. 다운로드 버튼 위 라이브러리 구성 화면으로 들어가 아래 화면으로 이동한다. 이 화면에서 Add External JARs로 이동해 HIbernat.. [JPA 따라하기] 1. Sample Database 설치. Server OS : Ubuntu 10.04 MySQL : 5.5.28, for debian-linux-gnu (x86_64) using readline 6.2 MySQL 역시 샘플 DB를 제공한다. 160MB 정도의 대용량을 샘플로 제공하는데, 이를 통해 JPA 프로젝트 생성을 할 수 있다. 샘플 DB의 Table역시 각 관계가 설정되어 있어 JPA에서 관계를 어떻게 표현하는지 알 수 있기에 다른 샘플 DB보다 적합하다. 자세한 것은 아래 URL을 참조. http://dev.mysql.com/doc/employee/en/employees-introduction.html MySQL Example Database download https://launchpad.net/test-db/employees-db-.. JPA Data Partitioning - Scaling the Database 참조 할 것 http://java-persistence-performance.blogspot.kr/2011/05/data-partitioning-scaling-database.html [펌] 프레임워크에 대한 불만을 정리한 글. 원글 : http://techblog.bozho.net/?p=358)** 이 글을 Korea Spring User Group의 송준이 님이 번역을 하여 글을 퍼옵니다. *지독하게 해로운 프레임워크, 그리고 복잡함* *(*http://techblog.bozho.net/?p=358)** 2011년 4월 29일 하이버네이트와 스프링같은 프레임어크는 업계 표준이다. JSF, EJB 등도 또한 업계 표준으로 많은 어플리케이션에 사용된다. 하지만 프레임워크 사용을 반대하는 사람들은 항시 있기 마련이다. 다루려는 주제는 "언어 불가지론(language-agnostic)"에 대한 것이고 자바를 예로 들겠지만, 모든 언어에 적용되는 내용이다. 프레임워크를 반대하는 일반적인 근거는 다음과 같다. - 프레임워크는 매우 복잡.. 이전 1 2 다음